あるとき、エディタ上で「入」の文字が化けてしまって困ったので原因を探ったのでメモしておきます。
経緯
エディタ上でファイル名をコピペしたら「入」の文字が化けてしまいました。エクスプローラ上で見ると一見普通の「入」の文字のように見えたのですが……。
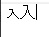
メモ帳に貼り付けたところ、明らかに様子がおかしいことに気付きました。
左が文字化けした「入」、右が手入力した「入」です。
何故か今回文字化けした「入」は半分くらいに潰れていますね……。字形が異なるということは、もちろん、文字コードも別です。ユニコードで見ると左が \u2F0A 、右が \u5165 です。
何でしょうこれ……。
調査
調べてみると、他にもこうした文字があることが分かりました。
⼊入
⼈人
⻄西
⾃自
⾞車
⼒力
⼿手
⾮非
⼤大
⼯工今回採集した例が上述。

メモ帳で見るといずれも半分くらいの大きさに潰れています。エクスプローラで見るとほとんど違いが分からないのですが、先述の通り文字コードが別なのでファイル名はしっかり別物と認識されます。
そのため、同じファイル名が複数あるように見えるというなかなか面白い困った状況に陥ります。
- PDFをコピペするとなぜ“文字化け”が起きてしまうのか 変換テーブル“ToUnicode CMap”が原因だった – ログミーTech
- PDFに文字化けを起こさせない対策法 もらったファイルは正規化で、作成ツールは対応済みを使え – ログミーTech
さらに調べた結果、原因が判明しました。原因は PDF でした。
- PDFの中のテキストは文字コードとは別の固有の番号で文字を出力しているが、Unicodeのような文字コードとは互換性はない
- 一応文字コードとPDF固有の番号の変換テーブルはある
- が、この変換テーブルがない PDF が存在する
- そうした場合、昇順で文字を参照するが本来の文字ではなく部首に当たる文字が先にヒットしてしまう
- この部首に当たる文字が先の半分潰れたような文字の正体
- 結果、コピペ等 PDF の中からテキストを抜く際に本来の文字ではなく、部首に当たる文字が抜き出される。その文字は通常の文字ではないため、一部の環境では化ける
ざっくり言うとこんな感じの原因の模様。確かに、今回のケースでも PDF の中から見出しのテキストをコピペしてファイル名にしていました。その際に先の条件に当てはまり、通常の 入 ではなく、 ⼊ を混入させてしまった、ということのようです。
原因が分かれば納得ですが、なんと面倒な……。
参考
- PDFをコピペするとなぜ“文字化け”が起きてしまうのか 変換テーブル“ToUnicode CMap”が原因だった – ログミーTech
- PDFに文字化けを起こさせない対策法 もらったファイルは正規化で、作成ツールは対応済みを使え – ログミーTech
(余談)
今回の件とは別件ですが、まあ文字コードがらみは厄介ですよね、というお話。